머신 러닝이란 무엇입니까?
이 정의는 Arthur Samuel에서 나왔습니다. Samuels는 최초의 실제 기계 학습 개척자 중 한 명을 인정합니다. 그리고 그는 실제로 1959년에 기계 학습이라는 용어를 처음 사용했습니다. 그는 기계 학습을 명시적으로 프로그래밍하지 않고도 컴퓨터에 학습 능력을 부여하는 연구 분야로 정의했습니다. 이것은 적절한 정의이지만 다소 모호합니다. 그리고 나는 그것이 몇 가지 정말로 중요한 개념을 설명한다고 생각합니다. 이렇게 정의하고 싶습니다. 머신 러닝은 함수를 예제에 맞추고 해당 함수를 사용하여 새로운 예제를 일반화하고 예측하는 것입니다. 이것은 알고리즘 또는 기계 학습 모델이 사용자가 제공하는 데이터를 기반으로 한다는 사실에 영향을 미치며, 이것이 예제에서 학습하는 방식입니다. 그런 다음 전체 목표는 학습된 모델을 사용하여 새로운 예에 대한 예측을 하는 것입니다. 그리고 이것은 정말 중요한 개념입니다. 즉, 머신 러닝 모델은 과거 데이터의 추세를 학습한 다음 미래 데이터에서 해당 추세를 찾아 예측합니다. 생각해 보면 우리 모두는 매일 이것을 합니다. 우리는 우리의 행동이나 미래의 관점을 조정하기 위해 과거 경험에서 배웁니다. 그 정의를 염두에 두고 기계 학습에 대한 더 간단한 정의는 패턴 일치입니다. 다시 말하지만, 모델은 많은 데이터를 받습니다. 그런 다음 공급된 데이터에서 추출한 모든 정보를 구성하는 방법을 배우기 시작합니다. 그런 다음 패턴을 학습하고 그것에 기능을 맞춥니다. 그런 다음 해당 기능을 사용하여 미래 데이터에서 이러한 패턴을 선택하여 예측합니다.
따라서 신용 카드 회사 모델에 대한 사기 탐지 모델과 같은 것은 과거 데이터를 기반으로 일반적으로 사기 청구를 나타내는 조건을 학습합니다. 그런 다음 해당 조건에 맞는 새로운 청구가 제시되면 청구가 사기임을 예측할 수 있습니다. 머신 러닝의 정말, 정말 간단한 예를 살펴보겠습니다. 그래서 그것은 단순한 단일 변수 선형 회귀가 될 것입니다. 따라서 이 플롯은 강우량을 기준으로 판매된 우산의 수를 보여줍니다. 따라서 모델은 강우량에 따라 얼마나 많은 우산이 판매될지 예측하려고 합니다. 이 이미지의 모델은 이 최적선으로 표시됩니다. 선에 대한 방정식은 y가 mx 더하기 b와 같다는 것을 기억할 수 있습니다. 여기서 y는 예측하려는 것 또는 이 경우에 판매되는 우산입니다. x는 예측에 사용하려는 것입니다. 이 경우 강우량, m은 선의 기울기, b는 y 절편입니다. 따라서 m과 b는 이 추세를 포착하기 위해 합리적인 모델에 적합하도록 훈련 데이터를 기반으로 모델이 학습하기를 원하는 매개변수입니다. 데이터를 기반으로 m과 b를 학습하면 이 최적선에 대한 방정식이 생성되고 해당 방정식이 모델입니다. 우리의 정의로 돌아가서, 함수를 예제에 맞추고 그 함수를 사용하여 새로운 예제를 일반화하고 예측하십시오. 우리는 이것의 첫 부분을 다루었고, 우리는 데이터에 맞는 함수나 모델을 가지고 있습니다. 이제 정확히 110밀리미터의 비가 내린 날의 예가 없더라도 110밀리미터의 비가 내린다면 제 모델을 기반으로 약 30밀리미터를 예상할 수 있다고 말할 수 있습니다. 판매하는 우산. 다시 말하지만 이것은 매우 간단한 예입니다. 그리고 일반적으로 작업에서 접하게 될 모델은 훨씬 더 복잡합니다.
기계 학습은 실생활에서 어떻게 생겼습니까?
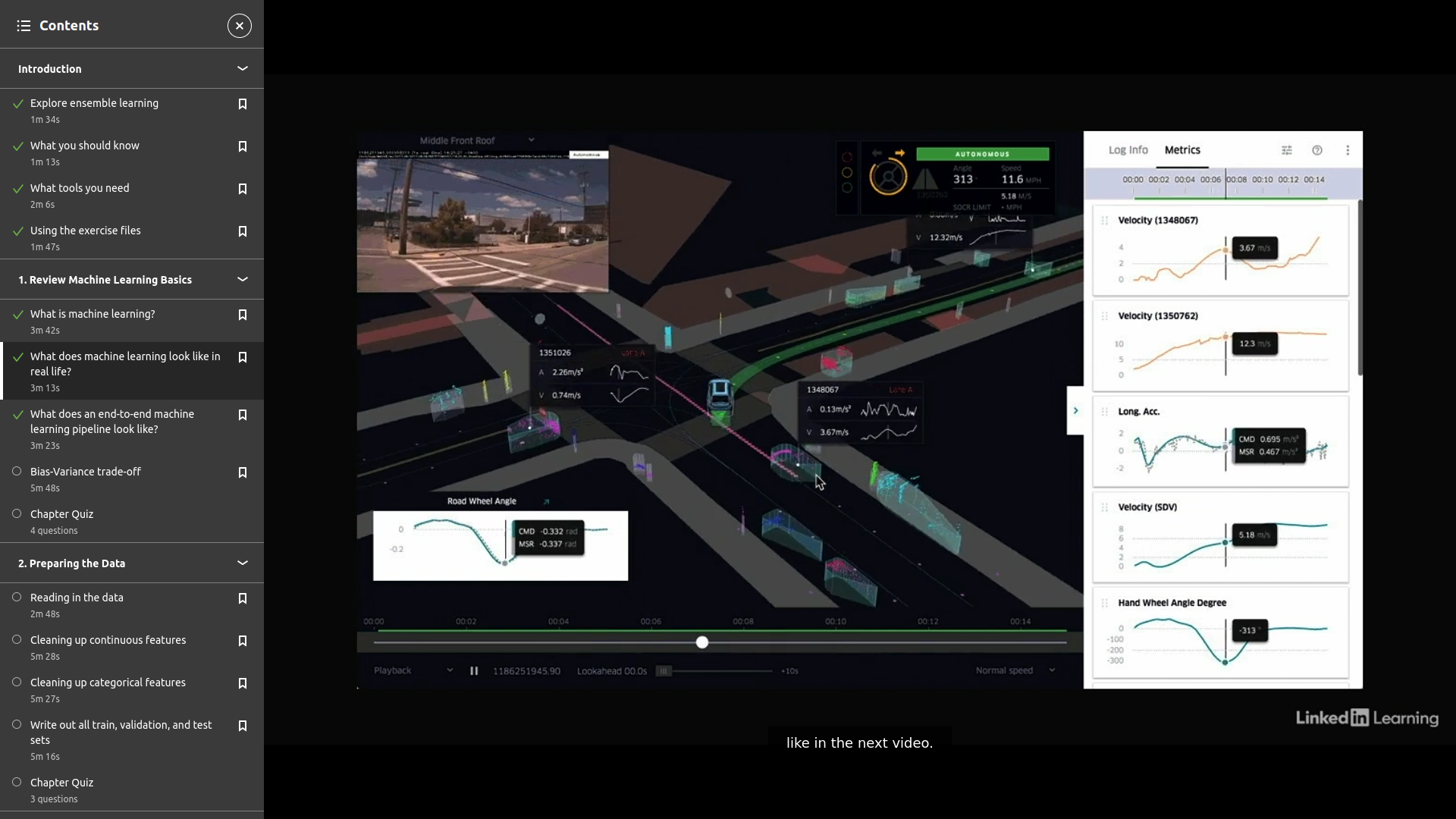
이제 머신러닝이 무엇인지에 대한 합리적인 이해를 바탕으로 우리 일상에서 머신러닝의 몇 가지 예를 살펴보겠습니다. 첫 번째 예는 개인 지원입니다. Siri, Google Home 또는 Amazon Echo를 통해서든 이 모든 음성 인식 소프트웨어는 기계 학습을 사용하여 구축됩니다. 이 작은 다이어그램은 Siri가 들은 것으로 생각하는 것을 어떻게 취하고 모델을 통해 실행하여 가장 가능성이 높은 말을 찾은 다음 일부 쿼리를 실행하여 응답을 반환하는 방법을 보여줍니다. 보다 구체적으로 말하면, 들은 것으로 생각하고 이를 사람이 실제로 질문했을 가능성이 가장 높은 것으로 부드럽게 만드는 부분이 여기에서 기계 학습 기능의 핵심입니다. 다음 예는 추천 시스템입니다. 우리는 말 그대로 Amazon 쇼핑에서 Netflix, Spotify, Facebook 친구 추천, Twitter에 이르기까지 이러한 것들로 둘러싸여 있습니다. 이러한 모든 추천 시스템은 기계 학습에 의해 구동됩니다. 이제 이것은 협업 필터링이라는 추천 시스템을 구축하는 데 사용되는 한 가지 방법의 매우 간단한 예입니다. 협업 필터링은 사용자 간의 유사성을 사용하여 권장 사항을 생성합니다. 따라서 이 예에서 Bob과 Tom은 모두 피자와 샐러드를 사고 즐겼습니다. 구매 및 평가 기록을 기반으로 Bob과 Tom의 취향이 비슷하다는 것을 알 수 있습니다. Bob도 탄산음료를 사서 즐겼지만 Tom은 그렇지 않았습니다. 따라서 시스템은 Tom에게 탄산음료를 추천해야 합니다. 협업 필터링이 작동하는 방식을 10,000피트에서 볼 수 있습니다. 기계 학습의 또 다른 예는 Uber 또는 Lyft와 같은 차량 공유를 사용하는 것입니다. 여기에서 머신 러닝을 사용할 수 있는 여러 가지 방법이 있습니다. 트래픽 기반 경로 효율성부터 라이더 위치, 드라이버 위치 및 트래픽을 기반으로 한 드라이버 라이더 페어링, Uber Pool에서 두 명의 라이더를 함께 페어링하는 효율적인 방법 결정에 이르기까지, 각 목적지 및 트래픽에 대한 출발점을 사용하여 해당 라이더를 적절한 드라이버와 짝을 지어줍니다. 그리고 이 모든 것이 이상적으로는 대규모의 대규모에서 밀리초 단위로 발생해야 합니다. Uber는 트래픽 데이터를 공개적으로 사용할 수 있게 했으며 Uber Movement라는 깔끔한 도구를 구축하여 주어진 시간과 요일에 여러 도시의 다른 지역에 도착하는 데 걸리는 시간을 보여줍니다. 마지막으로, 가장 최신의 가장 인기 있는 연구 및 구현 영역 중 하나는 자율 주행 자동차입니다. 이것은 머신 러닝의 일종인 딥 러닝을 사용하는 것입니다. 자동차를 운전할 때 머릿속에 떠오르는 모든 것에 대해 생각해 보십시오. 대부분은 몇 년 동안 운전을 하다 보면 본능적으로 옵니다. 제한 속도를 운전하고, 주변의 모든 차를 추적하고, 뒤를 돌아보고 있지 않은지 확인하고, 제동등을 주시하고, 정지 신호나 신호등을 찾고, 거리 표지판이나 랜드마크를 찾습니다. 이 모든 뉘앙스와 직관을 포착하려면 수년간 운전을 통해 우리의 두뇌가 학습한 이러한 모든 패턴을 학습할 수 있는 딥 러닝 네트워크가 효과적으로 필요합니다. 이제 기계 학습을 정의하고 실생활에서 몇 가지 예를 살펴보았으므로 다음 비디오에서 표준 기계 학습 파이프라인이 어떻게 생겼는지 조금 더 살펴보겠습니다.
종단 간 기계 학습 파이프라인은 어떻게 생겼습니까? What does an end-to-end machine learning pipeline look like?
이 응용 기계 학습 시리즈의 4개 과정은 각각 이 종단 간 기계 학습 파이프라인의 다른 부분을 다루기 위한 것입니다. 이 비디오의 끝에서 각 과정이 파이프라인에서 어디에 속하는지 설명하여 이 특정 과정이 이 시리즈의 다른 과정과 비교하여 어디에 있는지에 대한 구체적인 이해를 제공합니다. 하지만 이러한 각 영역에 대해 완전히 이해하지 못한 경우에도 걱정하지 마십시오. 나는 당신이 따라갈 수 있도록 이 과정의 각 단계에 충분한 컨텍스트를 제공할 것입니다. 지금은 매우 높은 수준에서 기계 학습 모델을 구축하는 프로세스를 빠르게 검토해 보겠습니다. 전체 데이터 세트로 시작하고 첫 번째 단계는 해당 데이터를 탐색하여 우리가 가진 기능의 유형, 모양, 대상 변수 또는 예측하려는 대상과의 관계를 실제로 이해하는 것입니다. 그런 다음 이러한 학습 중 일부를 사용하여 데이터를 정리합니다. 다음 단계는 데이터를 훈련, 검증 및 테스트 세트로 분할하여 모델을 적합하고 보이지 않는 데이터에 대해 평가할 준비를 하는 것입니다. 그런 다음 5중 교차 검증이라는 것을 사용하여 초기 모델에 적합하고 모델의 기준 성능에 대해 기대할 수 있는 것을 확인합니다. 그런 다음 5중 교차 검증을 사용하여 각 알고리즘에 대한 다양한 하이퍼파라미터 설정을 탐색합니다. 이 과정의 뒷부분에서 Scikit-learn의 GridSearchCV 도구를 사용하여 실제로 3단계와 4단계를 한 단계로 접는 것을 알 수 있습니다. 그런 다음 우리는 몇 가지 최고의 모델을 선택하고 검증 세트에서 서로를 평가할 것입니다. 마지막으로 검증 세트 성능을 기반으로 최상의 모델을 선택합니다. 그리고 우리는 이 모델이 보이지 않는 데이터에서 어떻게 수행될 것으로 기대할 수 있는지에 대한 완전히 편견 없는 관점을 얻기 위해 테스트 세트에서 이를 평가할 것입니다. 이 모든 단계는 과정 후반부에 진행되지만 앞서 언급했듯이 다른 과정을 반드시 수강할 필요는 없지만 해당 단계를 매우 빠르게 다룰 것입니다. 따라서 기계 학습을 처음 접하고 전체 프로세스에 대한 개요를 원하고 기계 학습 문제에 실제로 적용하는 데 필요한 기초 지식을 수집하려는 경우 기초인 응용 기계 학습을 수강하는 것이 좋습니다. 데이터를 탐색하고 정리하는 첫 번째 단계에 대해 자세히 알아보고 싶다면 응용 머신 러닝 기능 엔지니어링은 데이터에서 모든 가치를 실제로 추출하는 프로세스에 중점을 둡니다. 알고리즘인 응용 머신 러닝은 초기 모델을 피팅하고 하이퍼파라미터를 조정하고 모델을 최적화한 다음 최종 결과를 평가하는 프로세스에 중점을 둡니다. 이 과정은 몇 가지 다른 유형의 알고리즘을 다루며 광범위한 기계 학습 알고리즘 세트를 더 잘 이해하려는 경우 시작하는 것이 좋습니다. 이 과정은 실제로 알고리즘 과정과 같은 공간에서 진행되며 앙상블 학습자라고 하는 특정 알고리즘 클래스에 대해 자세히 알아볼 것입니다. 이제 우리는 기계 학습을 정의하고 실생활에서 몇 가지 예를 살펴보고 전체 기계 학습 파이프라인이 어떻게 생겼는지 살펴보기 위해 확대했습니다. 머신 러닝의 모든 것이지만 특히 앙상블 학습자를 이해하는 데 있어 편향-분산 트레이드 오프가 있습니다.
What does an end-to-end machine learning pipeline look like?
Selecting transcript lines in this section will navigate to timestamp in the video
- [Instructor] Each of the four courses in this applied machine learning series is intended to cover a different portion of this end-to-end machine learning pipeline. At the end of this video, I'll describe where each course falls in the pipeline so there's a concrete understanding of where this specific course lies relative to the other courses in this series. With that said, don't worry if you don't have a complete understanding of each of these areas. I'll provide enough context to each stage in this course to get you caught up. For now, let's quickly review the process of building a machine learning model at a very high level. We'll start with a full data set and the first step will be exploring that data to really understand the type of features we have, what they look like and how they relate to the target variable or the thing we're trying to predict. Then we'll use some of those learnings to clean the data. The next step is to split our data into training, validation and test sets to prepare to fit a model and evaluate it on unseen data. Then we'll use something called fivefold cross validation to fit an initial model and see what we can expect for a baseline performance of the model. Then we'll be using fivefold cross validation to explore a variety of different hyperparameter settings for each algorithm. You'll notice later on in this course that we actually fold steps three and four into one step using the GridSearchCV tool in Scikit-learn. Then we'll select a couple of our best models and we'll evaluate them against each other on the validation set. Lastly, we'll select the best model based on the validation set performance. And we'll evaluate it on a test set to get a completely unbiased view of how we can expect this model to perform on unseen data. We'll be running through all these steps a little later on in the course, but as I mentioned, I'll provide enough context so you don't have to necessarily take the other courses but we will be covering those steps very quickly. So if you're new to machine learning and want an overview of the entire process and want to gather the foundational knowledge that you need to really apply to any machine learning problem, I would strongly encourage you to take applied machine learning, the foundations. If you really just want to deep dive on the first step where we explore and clean the data, applied machine learning feature engineering focuses on that process of really extracting every last ounce of value out of your data. Applied machine learning, the algorithms, focuses on the process of fitting initial models, tuning hyperparameters, optimizing the model, and then evaluating the final outcome. That course covers a few different types of algorithms and would be a good place to start if you want to better understand the broad set of machine learning algorithms. This course is actually going to live in same space as the algorithms course and we're just going to deep dive into a specific class of algorithms called ensemble learners. Now that we've defined machine learning, looked at a few examples in real life and zoomed in to take a look at what a full machine learning pipeline looks like, let's take a quick aside in the next video to talk about a critical element in all of machine learning but especially in understanding ensemble learners and that's the bias-variance trade off.
Bias-Variance trade-off
바이어스-분산 트레이드오프
'python & DS' 카테고리의 다른 글
| 06 (0) | 2022.07.31 |
|---|---|
| 05 (0) | 2022.07.31 |
| 04 (0) | 2022.07.31 |
| python json parsing error (0) | 2022.07.22 |
| bz2 file read with pandas (0) | 2022.07.18 |