심층 신경망을 사용하여 사용자가 제공한 영화 리뷰의 감정 분류에 대해 설명합니다. LSTM(장단기 기억)과 CNN(컨볼루션 신경망)은 감정 분석에 사용되는 두 가지 인기 있는 심층 신경망입니다. 감정 분석은 5만 개의 영화 리뷰로 구성된 인터넷 영화 데이터 세트(IMDb)를 통해 수행됩니다. CNN과 LSTM 아키텍처는 개별적으로 사용되며 나중에 CNN-LSTM 아키텍처를 조합하여 사용됩니다. LSTM 아키텍처가 CNN 및 CNN-LSTM 아키텍처에 비해 성능이 뛰어난 각 아키텍처에 대해 정확도 및 손실 측정 지표가 표시됩니다. GRU, CNN, LSTM 및 CNN-LSTM 아키텍처의 정확도는 각각 53%, 85%, 87%, 85%입니다. 손실 함수에는 Adam 최적화 프로그램과 이진 교차 엔트로피가 사용됩니다. CNN-LSTM 모델은 장기 의존성에 매우 좋으며 정확도도 좋습니다.
소개
감성 분석은 자연어 처리(NLP)와 텍스트 마이닝 분야로 유명합니다. 제품 성공의 대부분은 인터넷 리뷰에 달려 있기 때문에 현재 가장 중요하고 흥미로운 연구 분야 중 하나입니다. 감정 분석을 통해 우리는 자연 언어와 인간의 감정 또는 판단이 어떻게 상호 작용하는지 이해할 수 있습니다. 그것을 생산한 사람에게 매우 중요한 것에 대한 개인의 관점을 검토하는 것은 우리에게 도움이 됩니다. 예를 들어, 요즘 같은 시대에는 온라인이나 리뷰어로부터 긍정적인 리뷰를 읽지 않고는 영화를 보는 사람이 아무도 없습니다. 상황은 이전 시대와 동일합니다. 과거에는 Naive Bayes 및 SVM [1] 과 같은 다양한 기계 학습 접근 방식을 사용하여 감정을 분석했으며 좋은 결과를 얻었습니다. .
데이터 양의 증가로 인해 Deep Neural Network 아키텍처는 최근 NLP 작업에서 눈에 띄는 개선을 보여주었습니다. 합성곱 신경망(CNN)은 구성과 국소적 분산으로 인해 이미지 분류에 가장 널리 사용되는 신경망 아키텍처 중 하나입니다. CNN의 혁신적인 식별 기술에 따라 감성 분석에 필요한 캐치프레이즈를 자연 텍스트에서 쉽게 찾을 수 있으며, 이는 이전 시대의 자연어 처리에서도 상당한 성능을 입증했습니다 . Naive Bayes, SVM[1]을 포함한 다양한 기계 학습 기술 은 과거에는 정서를 분석하기 위해 성공적인 결과를 얻었습니다.
심층 신경망 설계는 최근 정보 양의 확장으로 인해 NLP 작업에서 상당한 발전을 보였습니다. CNN(컨벌루션 신경망)은 구성성과 국소 불변성으로 인해 사진 분류에 가장 자주 사용되는 신경망 아키텍처 중 하나입니다. . 자연어 처리에서도 뛰어난 능력을 입증한 CNN의 새로운 식별 방법은 문장 분류를 위해 자연 텍스트에서 감정 분석에 필요한 캐치프레이즈를 쉽게 찾을 수 있도록 하며[3] 다양한 Convolution Neural Network 변형도 사용 했습니다 . CNN은 연결 수가 적기 때문에 훈련 시간이 단축되는 이점이 있습니다.
순환 신경망(RNN)이라고 하는 또 다른 유형의 신경망은 간단한 텍스트나 문장의 구조적 종속성을 정확하게 시뮬레이션할 수 있습니다. 그러나 Vanishing Gradient 문제로 인해 장기적인 종속성을 설명할 수 없습니다 [4] . 이는 장기 종속성을 유지할 수 없고 결과적으로 문장 구조를 정확하게 표현할 수 없음을 의미합니다. [4] 에서는 장기 종속성을 제공하는 Vanilla RNN의 향상된 변형인 LSTM을 제안했습니다. LSTM의 사용은 작업 번역, 그림 캡션 작성, 질문 답변 및 문장의 다음 단어 예측의 구조적 종속성에 크게 의존하는 다양한 NLP 작업에 널리 퍼져 있습니다. [5]최근 LSTM이 텍스트 감정 분석에서 얼마나 잘 수행되는지 보여주었습니다. LSTM 훈련은 CNN 아키텍처 훈련보다 시간이 훨씬 오래 걸리기 때문에 가장 간단한 LSTM-CNN 아키텍처를 선택했습니다. 감정 분류를 위한 특징을 추출하기 위해 LSTM-CNN을 사용했습니다. 리뷰에 사용된 문장은 먼저 본 논문에서 설명한 단어 임베딩 방법을 사용하여 벡터 공간으로 변환되었습니다. 긍정적인 감정과 부정적인 감정을 분류하기 위해 수집된 특징을 다층 퍼셉트론 네트워크에 공급하기 위해 LSTM-CNN, CNN 및 LSTM의 세 가지 고유한 신경망 아키텍처가 사용되었습니다. 이 논문의 목적은 IMDb frrdback 데이터 세트에서 분리 결과를 만드는 최적의 심층 신경망 토폴로지를 식별하는 것입니다. 신경망 프레임워크 Keras [6], 아키텍처를 개발하기 위해 구축된 고급 API입니다.
감정 분석은 고객이 브랜드, 제품, 실제 문제, 비즈니스, 가상 실체에 대해 어떻게 생각하는지 결정하는 데 중요한 역할을 합니다. 감정 분석은 주제에 대한 사용자 평가 연구에 도움이 되므로 리뷰의 감정을 기반으로 결론을 도출할 수 있습니다.
기사의 나머지 섹션은 다음과 같이 구성됩니다. 섹션 II에서는 감성 분석과 관련된 작업을 설명합니다. 이 논문에서 활용된 구조는 섹션 III 에서 검토됩니다 . 실험 결과는 섹션 IV 에서 설명됩니다 . 마지막으로 섹션 V에서는 실험 연구를 기반으로 결론을 설명했습니다.
관련된 일
A. 어휘 기반 방법
어휘 기반 접근 방식은 텍스트의 유효 평점이 개별 단어의 유효 점수의 합으로 계산될 수 있다고 가정합니다. 개별 단어의 유효 점수를 기반으로 다양한 구성 기술을 사용하여 텍스트의 유효 점수를 결정할 수 있습니다. . 산술평균은 실용적인 합성방법이다. 즉, 이 문장의 각 단어의 평균 VA 값은
B. 회귀 기반 방법
단어 수준과 문장 수준 모두에서 VA 예측을 위한 회귀 기반 기술이 광범위하게 연구되었습니다. Weiet al. [10]은 선형 회귀를 사용하여 단어 수준에서 VA 등급 영어를 중국어 용어로 전환했습니다. VA 예측을 위해 Malandrakis et. 알. [11] 커널 함수를 사용하여 단어 유사성을 결합했습니다. Yu 등은 가중치 그래프 접근법을 사용했습니다. [12] 및 Wang et al. [13]감정적인 단어의 VA 등급을 반복적으로 결정합니다. 최종 감정 점수를 예측하기 위해 구문 수준의 구문 수준 어휘집에 선형 회귀 모델을 사용하는 것을 제안했습니다. 정서적 어휘집에서 감정 등급을 계산할 때 후보 텍스트는 개별 단어로 분류됩니다. 어휘집에 포함되지 않은 용어를 제거하기 위해 불용어 목록이 포함됩니다. 그런 다음 텍스트의 감정 점수와 평균 단어 점수를 사용하여 회귀 모델을 구축합니다.
Paltoglou와 Thelwall [14] 은 낮은 값에서 큰 값까지의 5단계 척도를 사용하여 문장이나 문서의 원자가 및 각성 수준을 예측했습니다 . 저자는 감정 예측 문제를 분류 및 회귀 관점에서 조사했습니다. BoW 기능을 기반으로 두 가지 접근 방식이 모두 사용됩니다. 그런 다음 분류 및 회귀를 위해 SVM(지원 벡터 머신) 및 지원 벡터 회귀( ϵ − SV R )가 활용됩니다. 그들의 실험 결과는 또한 회귀 방법이 일반적으로 더 작은 규모의 실수를 초래한다는 것을 보여줍니다.
방법론
A. 데이터 세트 설명
가장 큰 IMDb 영화 리뷰 데이터 세트 중 하나는 [7] 입니다 . 데이터 세트에는 50,000개의 영화 리뷰가 있으며 긍정적인 리뷰와 부정적인 리뷰의 두 가지 범주로 나뉩니다. 모든 피드백이 일련의 단어 인덱스로 암호화된 이 데이터 세트는 Keras [6] 에서 찾을 수 있습니다 . 그런 다음 데이터 세트는 80:20 비율로 훈련 데이터와 테스트 데이터로 나누어졌습니다. 훈련 샘플의 20%를 사용하여 검증 데이터 세트가 생성되었습니다. 아키텍처 교육을 단순화하기 위해 짧은 리뷰를 제로 패딩하여 모든 리뷰의 길이를 동일하게 만들었습니다.
B. 워드 임베딩
자연 텍스트와 관련된 대부분의 NLP 작업에 대한 주요 요구 사항 중 하나는 단어 삽입입니다. 어떤 아키텍처에도 적합하도록 모든 단어는 n차원으로 변환됩니다. 지금 이 작업을 수행하는 방법에는 두 가지가 있습니다. Bag of Words 모델을 사용한 단어 임베딩과 원-핫 키 인코딩이 그 중 두 가지입니다. Bag of Words는 메모리를 낭비하는 상대적으로 희박한 형식인 반면, Word Embedding은 모든 용어를 긴밀하게 표현합니다. 단어 임베딩은 연관된 단어 유형을 n차원에 모아두는 방식으로 수행됩니다. 각 포함된 단어의 벡터 차원은 여기서 숫자 n으로 표시됩니다. 사전 훈련된 두 가지 단어 임베딩 모델이 있습니다. Word2vec [2] 및 장갑 [8]두 가지 예입니다. 8000개의 개별 단어로 구성된 어휘의 각 단어는 100차원 벡터로 제공되지만 Keas에서 제공하는 임베딩 레이어를 사용했습니다. 모델은 IMDb 영화 데이터를 사용하여 학습됩니다.
C. 컨볼루셔널 신경망
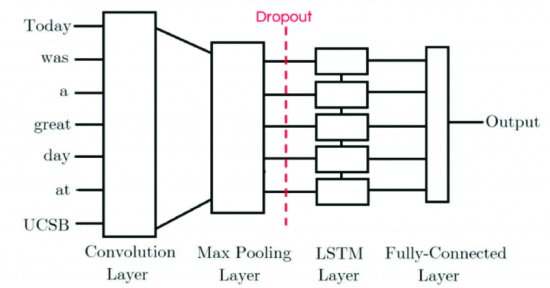
세 개의 레이어가 컨볼루션 신경망의 대부분을 구성합니다 [2]. 하나는 컨볼루션 레이어에서 필터와 입력 행렬을 혼합합니다. 종종 필터라고도 하는 커널은 특정 특성을 식별하는 데 사용됩니다. CNN에는 수많은 필터가 사용됩니다. Glorot 균일 분포는 필터 가중치의 초기화 지점 역할을 합니다. 이후 네트워크 훈련을 통해 특정 특성을 탐지하기 위해 가중치를 부여했습니다. 풀링 레이어라고 하는 두 번째 레이어는 한 레이어의 마지막 뉴런 레이어가 다음 레이어의 단일 뉴런 레이어와 병합되는 곳입니다. 풀링에는 최대 풀링, 평균 풀링 등 다양한 종류가 있습니다. Max Pooling은 대부분의 상황에서 사용됩니다. 풀링을 통해 변환 불변성을 제공할 수 있습니다. 두 컨볼루션 레이어 사이에는 풀링 레이어가 적용됩니다. 컨볼루션 및 풀링 레이어는 세 번째 이전에 사용됩니다. 완전 연결 레이어입니다. 레이어의 임무는 Convolution 레이어에서 발견된 낮은 특성으로부터 더 높은 수준의 결론을 도출하는 것입니다. CNN은 임베딩 레이어를 통과한 각 단어에 대한 100차원 벡터에 대해 각 리뷰마다 500개의 단어를 입력으로 받습니다. 특성을 얻기 위해 2개의 컨볼루셔널 레이어가 사용되었고, 2개의 풀링 레이어가 사용되었습니다. 컨볼루셔널 레이어에서는 ReLU의 활성화 함수를 사용했습니다.[9] . 위 2개 레이어의 출력은 분류를 위해 완전 연결 레이어에 제공되고, 추출된 특징을 은닉 레이어에 공급합니다. 이진 분류 문제인 경우 출력 레이어에는 시그모이드 활성화 함수 노드가 하나만 있습니다.
D. 장단기 기억
LSTM은 순환 신경망의 새로운 버전입니다. LSTM과 RNN의 주요 차이점은 LSTM에서는 존재하는 입력을 기반으로 정보를 저장하거나 업데이트할 수 있는 메모리 셀입니다. LSTM에는 망각 게이트, 입력 게이트 및 마지막 출력 게이트가 있습니다. Forget Gate 레이어는 메모리 셀에서 어떤 데이터를 제거해야 하는지 결정하는 Sigmoid 레이어입니다. 두 번째 계층인 입력 게이트 계층은 메모리 셀에 어떤 새로운 데이터를 저장할지 결정합니다. Sigmoid 레이어와 Tanh 레이어의 두 레이어로 더 나뉩니다. 연관된 LSTM 셀의 출력은 세 번째 계층인 출력 게이트 계층에 의해 결정됩니다. 게이트는 수학적으로 다음과 같이 정의할 수 있습니다.

망각, 입력 및 출력 게이트는 여기서 f t , i t 및 O t 로 표시됩니다 . 레이어 바이어스 인자는 문자 bf 및 b o 로 표시됩니다 . 현재 단위의 입력과 출력은 각각 x t 와 h t 로 표시되는 반면, h t− 1 은 x t 의 이전 단위인 x t− 1 의 결과입니다 .tanh 및 sigmoid 레이어는 각각 tanh 및 sigmoid 레이어로 표현됩니다. 주어진 LSTM 네트워크는 CNN과 동일한 입력을 받습니다. 모델의 복잡성을 줄이기 위해 Embedding Layer 다음에 LSTM 네트워크에는 하나의 LSTM 레이어만 사용됩니다. 이와 유사하게 MLP 네트워크에는 분류를 위해 LSTM 추출 기능이 제공되었습니다. 출력 레이어는 CNN 네트워크와 동일합니다.
E. CNN-LSTM
감정 분류에 초점을 맞춘 범주형 방법에 대한 차원적 접근 방식을 비교하면 이진 분류를 가정하면 보다 정확한 감정 분석(즉, 긍정적 및 부정적)을 얻을 수 있습니다. 이 기사에서는 텍스트의 VA 등급을 예측하기 위해 지역 CNN과 LSTM의 두 부분으로 구성된 트리 구조의 지역 CNN-LSTM 모델을 제시합니다. 제안된 지역 CNN은 전체 텍스트를 입력으로 간주하는 전통적인 CNN과 달리 입력 텍스트를 여러 영역으로 나눕니다. 이를 통해 지역의 중요한 정보를 적절하게 추출하고 가중치를 부여하여 VA 예측에 부여할 수 있습니다. VA 예측의 경우 이러한 데이터는 지역 CNN과 LSTM을 결합하여 예측 프로세스에서 고려된 문장 내부에 포함된 지역 데이터와 구문 간의 장거리 종속성을 순차적으로 결합합니다.
A. 지역 CNN-LSTM 모델
각 지역의 로컬 n그램 특징은 처음에 컨벌루션 레이어를 사용하여 추출됩니다. 영역 행렬 M ∈ ℝ d ×| 뷔 | 어디 | 뷔 | 는 영역의 어휘 크기이고 d는 단어 벡터의 차원이며 모든 단어 임베딩이 누적됩니다. 예를 들어 그림 4 에서 영역 행렬 x ri , x rj 및 x rk 는 영역의 단어 벡터를 결합하여 생성됩니다.아르 자형나= {승1나는 _,승2나는 _, … ,승나나는 _},아르 자형제이= {승1rj _,승2rj _, … ,승나rj _}그리고아르 자형케이= {승1r k,승2r k, … ,승나r k}우리는 각 영역에서 L 컨벌루션 커널을 사용하여 학습된 로컬 n-그램 기능을 사용합니다. 우리는 각 영역에서 L 컨벌루션 커널을 사용하여 학습된 로컬 n-그램 기능을 사용합니다. 커널 F l (1 ≤ l ≤ L )은 특징 맵을 생성합니다.와이엘NΩ 단어 xn :n+Ω −1 의 창에서 다음과 같이
최대 풀링은 컨벌루션 레이어의 출력을 샘플링합니다. 풀링 크기 s의 max 연산을 각 커널의 출력에 적용하는 것이 풀링을 수행하는 가장 일반적인 방법입니다. 가장 중요한 정보를 보존하기 위해 다양한 지역의 로컬 종속성을 최대 풀링 계층을 통해 얻을 수 있습니다. 벡터로 평탄화된 후, 획득된 영역 행렬은 순차 레이어에 공급됩니다.
순차 레이어는 지역 간의 장거리 종속성을 캡처하기 위해 지역의 각 벡터를 텍스트 벡터로 순차적으로 통합합니다. 순차 레이어의 벡터 구성을 위해 LSTM이 도입되었습니다. LSTM 셀이 모든 영역을 통과하는 순차 레이어의 최종 숨겨진 상태는 VA forcasting text 표현을 고려합니다.
나. 지역분할 전략
순차 기법을 사용하여 텍스트의 모든 개별 문장을 하나의 영역으로 만드는 것은 간단한 방법 중 하나입니다. 예를 들어, 텍스트가 3개의 문장으로 구성되어 있으면 세 영역 모두 해당 문장을 받게 됩니다. 가장 중요한 정보는 별도의 컨벌루션 및 최대 풀링 레이어를 사용하여 각 영역에서 추출된 후 세 개의 LSTM 순환 단위가 있는 전역 순차 레이어에 공급됩니다. 이 전술은 사용하기 간단하지만 문장 길이의 여유가 크면 상당히 불균형해질 것입니다. 거대한 문장에서 중요한 특성을 얻기는 어려울 것입니다.
순차 방법보다 텍스트의 의미를 더 정확하게 캡처하는 대체 방법은 입력 텍스트를 트리 구조 토폴로지로 구문 분석하는 것입니다. 주어진 텍스트는 구문 분석 트리의 트리 깊이에 따라 영역으로 분리될 수 있습니다. 이러한 영역은 단어, 구, 절, 문장 또는 전체 단락(모두 언어 표현 기능 블록)일 수 있습니다.
F. 게이트 순환 단위
3번 게이트는 내부 상태를 관리하지 않습니다. LSTM 순환 유닛의 내부 셀 상태에 보관된 데이터는 게이트 순환 유닛의 숨겨진 상태에 통합됩니다. 다음 반복 단위가 가져오는 데이터 그룹입니다. GRU 게이트의 유형은 다음과 같습니다.
- Update Gate(z): 이전 데이터의 양을 결정합니다. 이는 LSTM 순환 장치의 출력 게이트와 유사합니다.
- Reset Gate(r): 이 목적을 위해 폐기될 이전 정보가 이 게이트가 사용됩니다. 망각 및 입력의 게이트 순환 단위 게이트는 LSTM 게이트와 유사합니다.
- Current Memory Gate( h t ): Gated Recurrent Unit 네트워크에서는 고려되지 않습니다. 입력 변조 게이트는 입력 게이트의 일부이며 입력에 일부 비선형성을 제공하고 입력을 평균 0으로 만드는 데 사용되며 재설정 게이트에 통합됩니다. 리셋 게이트의 일부가 되면 이전에서 미래로 전송되는 정보의 효과가 감소합니다.
실험적 분석
A. 실험 설정
Google Colab에서는 세 가지 아키텍처가 모두 구현되어 더욱 빠른 컴퓨팅 환경이 만들어졌습니다. 아키텍처의 학습 기간 동안 감소가 발생하고 8 epoch 이후에는 감소가 중단되므로 배치 크기 782로 8 epoch 동안 CNN 아키텍처 모델을 학습했습니다. 동일한 5 epoch 동안 배치 크기 782로 LSTM 네트워크를 학습했습니다. 이유. LSTM-CNN 네트워크 배치 크기는 6개 에포크입니다. Binary Cross-Entropy에 의해 결정된 손실 함수를 줄이기 위해 Adam 최적화 프로그램이 사용되었습니다. 네트워크의 과적합을 방지하기 위해 Dropout 접근 방식을 적용했습니다.

나. 결과 및 성과분석
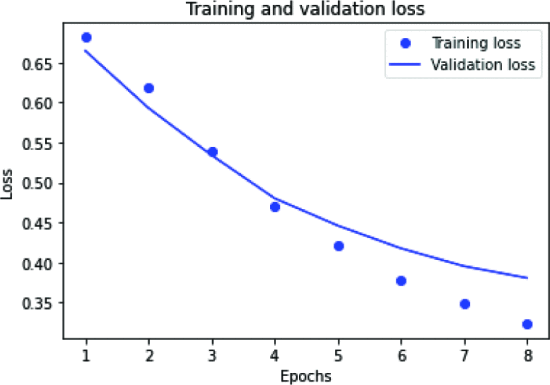
IMDb 피드백은 호의적이거나 부정적일 수 있으므로 데이터 세트는 이진 분류 문제를 해결합니다. IMDb 영화 리뷰는 호의적이거나 비호의적일 수 있으므로 데이터세트는 이진 분류 문제를 해결합니다. 그림 2는 LSTM 모델의 정확도를 설명합니다. Lstm 모델 정확도는 다른 모델에 비해 훨씬 우수하고 과적합이 적습니다. 훈련 중에는 잘 수행되지만 검증 중에는 정확도가 낮았습니다. 8개 에포크에서는 훈련 및 검증 정확도에서 큰 차이를 볼 수 없었습니다. 그림 3은 학습 손실과 검증 손실이 표시된 LSTM 모델의 손실을 설명합니다.
그림 4는 CNN 모델의 정확도를 설명합니다. CNN은 훈련 중에는 잘 수행되지만 검증 중에는 수행되지 않습니다. 그래프에서는 매 에포크마다 훈련 정확도와 검증 정확도가 서로 반대되는 것으로 보입니다. 8 에포크에서는 큰 차이를 볼 수 있습니다. 훈련과 검증 사이의 그래프.
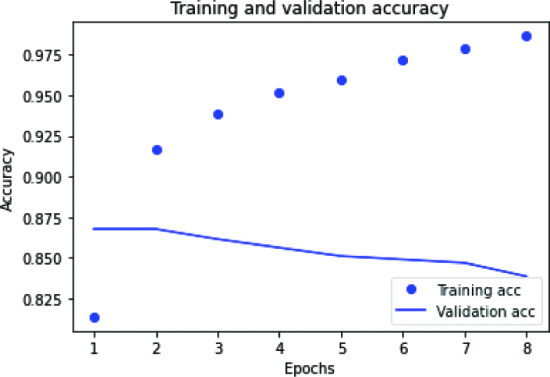
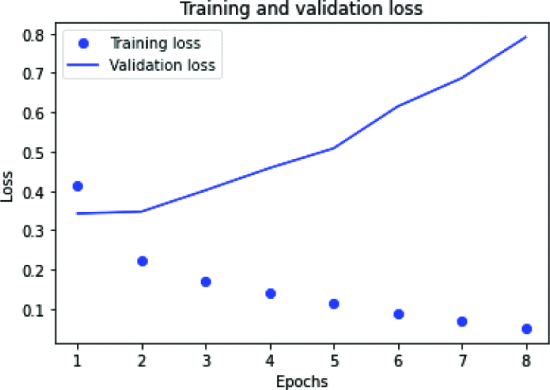
그림 5 에서 손실은 2~8 에포크 검증 사이에 있고 훈련 손실은 증가하는 것을 볼 수 있습니다.
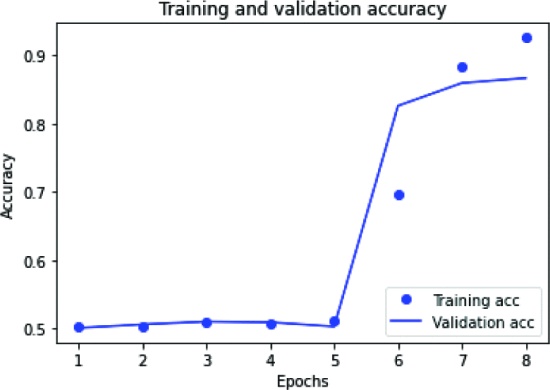
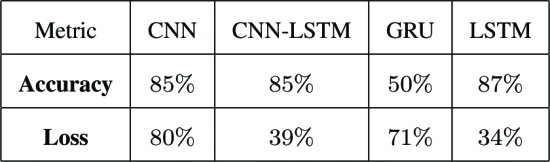
그림 6은 CNN-LSTM 모델의 정확도를 나타내며, 1~5 에포크에서는 훈련 및 검증과 유사하지만 6 에포크부터는 훈련과 검증 에포크 간에 차이가 있음을 알 수 있습니다.

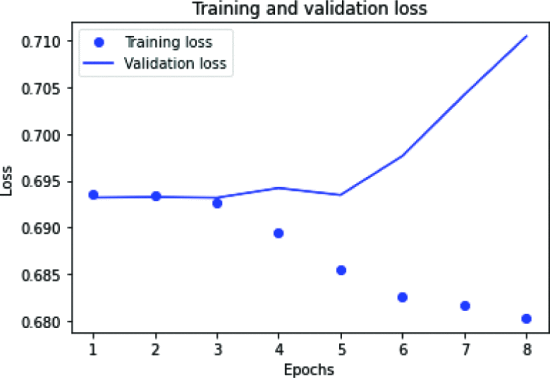
그림 7은 CNN-LSTM 모델의 손실을 나타낸다. 1~5 에포크 손실은 훈련과 검증과 유사하지만 6 에포크 손실 이후에는 감소했지만 검증에서는 감소했지만 훈련 에포크 손실은 여전히 큰 차이가 없음을 볼 수 있는 게이트 반복 신경망의 정확도 플롯은 다음과 같습니다. 도 9 에 도시된 바와 같이 . 여기서 과적합이 발생하면 훈련 정확도가 검증 정확도보다 훨씬 좋습니다. GRU 신경망의 훈련 및 검증 손실은 그림 8 과 같습니다 . 여기서 훈련 손실은 검증 손실에 비해 적습니다.
결론
온라인 데이터의 양이 급속히 증가함에 따라 감정 분석이 점점 더 중요해지고 있습니다. 여론을 예측하고 예측하기 위해서는 인터넷 리뷰나 소셜미디어 등의 감성분석이 필요하다. 섹션 IV 및 표 I 에 제공된 모든 모델에 대한 정확도 플롯에서 LSTM 아키텍처 정확도는 CNN-LSTM보다 2% 더 높고 손실도 CNN-LSTM보다 5% 적다는 결론을 내렸습니다. CNN-LSTM 아키텍처는 개별 LSTM에 비해 훈련 시간을 단축합니다. LSTM은 CNN, LSTM 및 GRU 아키텍처에 비해 성능이 매우 뛰어납니다. 8 epoch에 대해 훈련되고 테스트된 모델과 adam 최적화 프로그램은 더 빠른 수렴을 위해 사용되었으며 Binarycross 엔트로피는 손실 함수로 사용되었습니다.
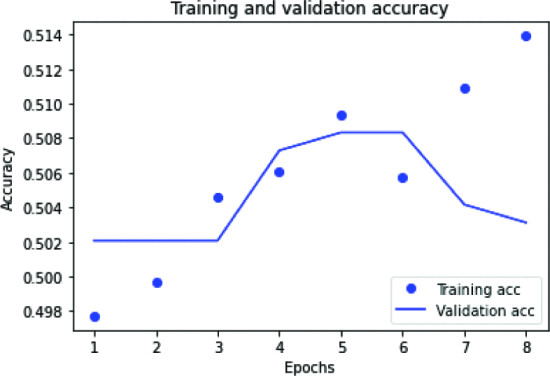
GRU의 정확성
'딥러닝' 카테고리의 다른 글
| AlexNet vs SNN torch /w MNist dataset (0) | 2023.09.28 |
|---|---|
| MIT deeplearning class (0) | 2023.09.09 |
| global vectors (0) | 2023.08.31 |
| opendata set (0) | 2023.02.06 |
| tensorflow without GPU (0) | 2023.01.30 |